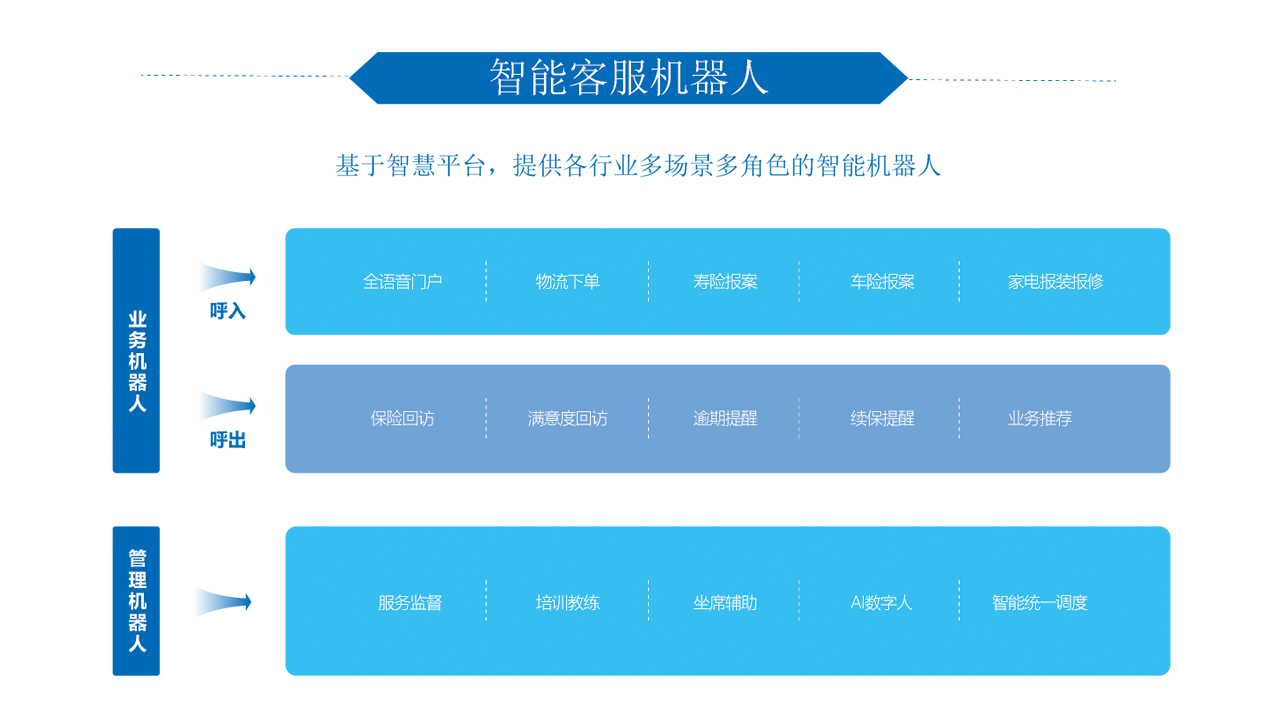
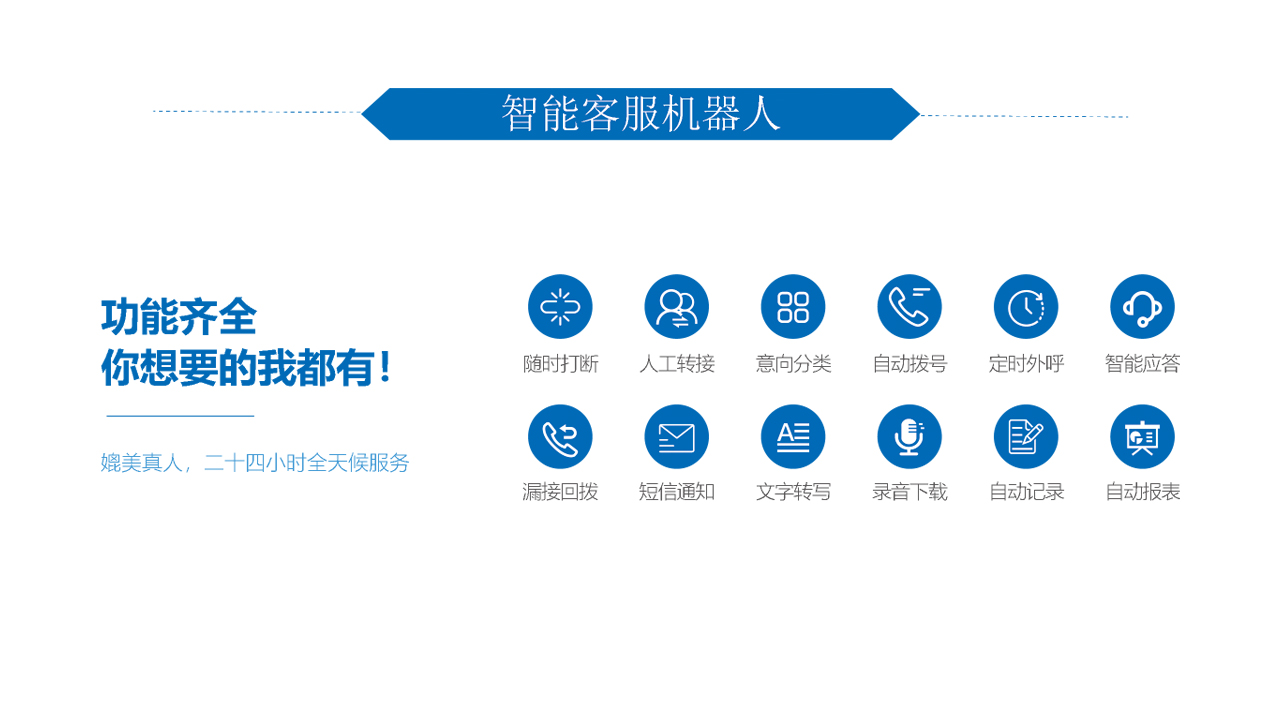
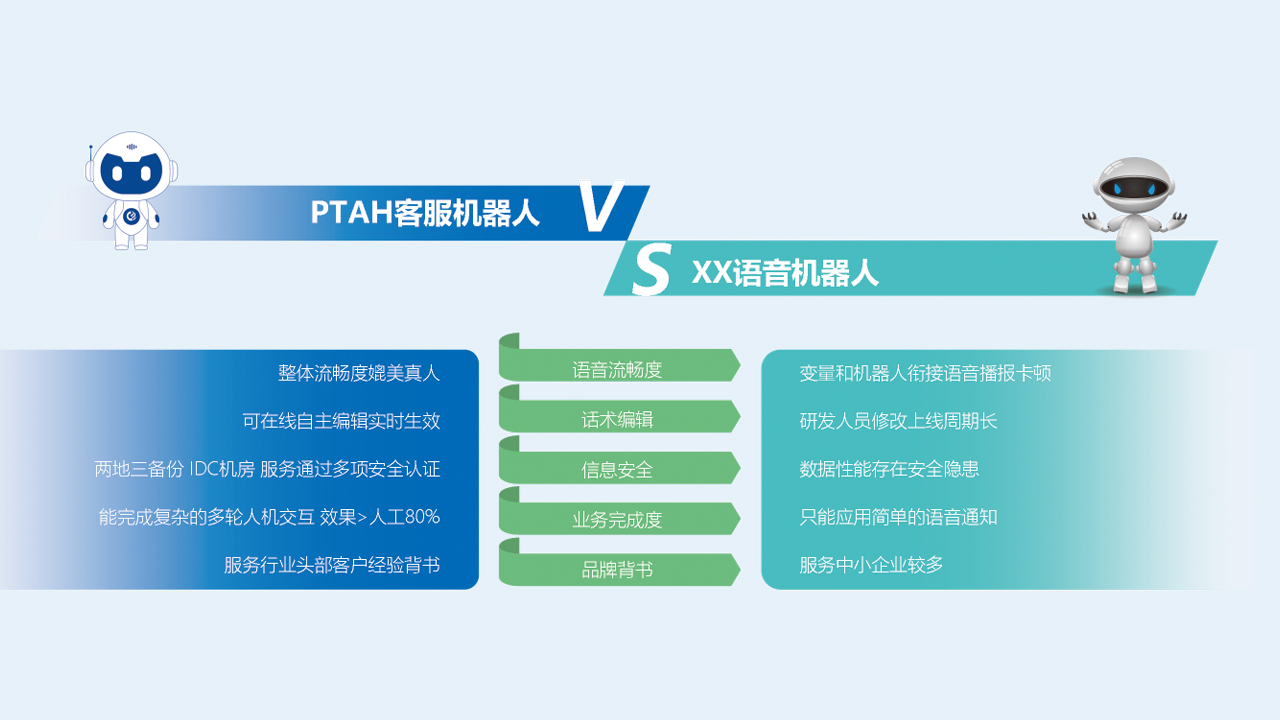
回顾人机交互的发展,其实就是一个不断改造计算机解放人的过程。在最早的计算机中,键盘是唯一的输入设备。后来,有了图形界面GUI,就有了鼠标。但是键盘鼠标本身需要更高的学习成本。让他们试着观察你年迈的父母使用鼠标,准确控制鼠标,掌握单双击的速度和节奏,并不容易。
变化二:从常规指令交互到自然语言交互。自然语言交互不限于VUI,也包括GUI上的自然语言交互。
目前来看,未来主流的交互方式是不确定的。但有一点可以肯定,更高效、更自然、更贴近人类本能的方向是未来交互的方向。就像现在的VR、AR、MR技术,其实都是一个模拟人与现实交互的过程。为什么会是这样的趋势?是因为人机交互最终是与人的感官进行交互的,而人的感官所适应的系统是在几百万年的进化过程中与自然相互作用的过程。所以人与自然的互动是最高效最舒服的。所以现在的人机交互应该尽量模仿人与自然交互的这样一种方式。
Echo的威力:亚马逊Echo最初除了语音交互之外只提供语音交互,保证了语音交互的纯粹性和持久性,用户只能使用语音。和siri相比,没有屏幕上的文字反馈,就像和人说话一样。在习惯之后,用户将继续通过语音与设备进行交互。而且Echo的定位非常准确,定位在家用设备,用户体验非常好。可以自然控制音乐播放、闹钟设置、语音控制智能家电的开关(开灯关灯、拉窗帘等。).
集成传感器:想象一下,你现在想给一个朋友转一笔钱。今天看来,你需要打开支付宝或者某银行App,输入金额,验证码,密码,经过一系列复杂的流程,钱就可以转出来了。以后你只需要在家里对你的房子说,你想把钱转给谁,几秒钟之内,就会有一个声音告诉你,已经打完了。在一系列传感器的帮助下,从一系列数据如你的声线和身体体征,语音是机器交互最自然的范式。
但在适合语音交互的场景和任务中,语音交互会成为主流的交互方式。
CLI(命令行界面)命令行界面:由打字机演变而来,用户输入命令,计算机执行操作。命令是以代码的形式出现的,用户必须记忆文本代码才能操作。
GUI(图形用户界面)图形用户界面:图形显示,鼠标操作计算机。施乐发展,乔布斯通过个人电脑普及到大众消费市场。与CLI相比,新用户的学习成本大大降低。GUI具有“所见即所得”的特点,用户可以通过“窗口、按钮、图标和菜单”等隐喻性组件更有效地与计算机交流。
NUI(自然用户界面)自然用户界面:用户使用人类自然的方式,如语音、面部表情、手势、移动身体、旋转头部等。,完成操作。无论是GUI还是CLI,都必须要求用户先学会软件开发者预设的操作。NUI更自然简单,符合人性,用户学习和运营成本更低。]
触摸交互到语音交互:触摸交互从电阻屏手写笔到电容屏手指触摸。乔布斯推出iPhone,改变了人机交互的方式,一种更自然的交互方式。人与机器的交互方式是不断更新优化的,每十年就会有一代人的变化。现在距离第一代iPhone已经过去10年了,我们不会一直停留在触控交互上。一种新的交互方式出现了——语音交互。
2.语音交互的场景有限:不适合嘈杂的环境,也不适合安静的环境。
主动跟你说话:现在所有的语音助手还是被动说话。你得先下命令,他们才会回复。但是想象一下Google Now,深度学习和大数据准备充分。他们可以预测你下一步要去哪里,你会遇见谁,甚至你在想什么。他们只需要通过语音输出这些信息。与Google Now相比,你不再需要点亮手机来查看这些智能提醒。随时随地都会有一个声音主动和你说话。
4.语言交互效率低。当你在网站上购物时,是直接选择你想要的东西方便还是读这个物品的名称方便?
神经元可能是未来效率最高的,可以直接通过数据把人的意识或者想法传到云端,不用看。神经元应该用什么载体来表达?大概是可穿戴设备之类的,或者是贴近皮肤或者植入皮肤的芯片。现在还不能确定,因为意识能否转化为数据还没有解决。
所以在亚马逊推出Echo之后,我们看到了语音交互真正人性化的场景。谷歌主页、苹果HomePod和微软Invoke紧随其后。
音乐:
新闻获取
信息获取:搜索查询、交通、地理、天气、时间等信息
生活助手:闹钟、定时器、日程、todolist
br/] [其实这个方案是用户的另一种方式。苹果手机用户很少或偶尔使用语音助手。手机作为个人设备,多用于公共场合。用语音给手机下命令是不自然的。据统计,只有3%的用户会在公共场合使用siri。
耳朵是人类的主要器官,但不能说耳朵是最重要的器官。但是,眼睛和视力的使用占了70%。对于信息交互来说,嘴巴和耳朵属于说话、收发等人机交互的模型,是人与人之间的交互。语音可能占20%,触觉和嗅觉可能占剩下的10%。说到语音交互,现在讨论的重点其实是人机交互,人和机器的交互,人和云的交互。未来所有的设备都是智能的,有云,有语音,有屏幕,有动手。语音本身有很多局限性,刚才提到的一个就是它本身传递的信息量是有限的。第二是语音交互的效率比较低。同样的东西,人眼可以看到,人耳可以听到,视觉接受的速度远远超过说话的速度。
变化:从功能设计到场景设计。例如,当你在做饭和开车时,在这种情况下,它的VUI比GUI更有效。
好的交互方式应该是符合人的直觉的,也就是好用的。你可能在很多地方读到过乔布斯有一个要求:iPhone可以无障碍地从三岁小孩使用到七十岁老人,所以只保留一个实体Home键,让人别无选择,也不用思考。一切都可以从这里照亮。
不能说语音是一种主流的交互方式,因为语音能传递的信息量是有限的。不能说目前语音交互的智能音箱概念很火,所以我们认为语音交互会成为主流的交互方式。
语音交流更符合人的本能
婴儿先学会说话,再学会写字和阅读。从人类进化的角度来看,手势和声音也是先于文字产生的。人在看书的时候,往往会不自觉地把眼睛里的文字转换成大脑里的声音。这种阅读方式虽然不一定高效,但仍然是人类本能的一种习惯。
1.语音交互的准确率并不理想。
语音交互是对手和眼睛的进一步解放。整个过程只需要说和听。对于身体来说,感官体验和职业肯定更轻,而且相对于鼠标、键盘、遥控器甚至触摸屏来说,作为一种交互方式来讲,学习成本显然是最小的。(内容来自知乎:风一样的男人)
【人机交互】语音交互的本质是人机交互。人机交互是对系统和用户之间交互关系的研究。该系统可以是机器或计算机系统和软件。通过人与计算机的交互、交流和信息交换,产生一系列的输入和输出,进而完成一项任务或一个目的。语音交互就是用语音作为信息载体与机器进行交互。
语义理解是指在一些指定的话题中,人工智能设备可以理解人说的话,但目前的技术无法理解一般的话题,这也是行业内的难题,但即使是指定话题的理解也已经很有价值了。亚马逊、谷歌、rokid在语义理解上也各有优势。亚马逊在语义理解技术的产品化和工程化方面已经做到了极致。通过产品设计和技术架构设计,将成熟的技术集成到优秀的产品中。谷歌在算法和数据方面的能力最强。rokid虽然是一家创业公司,但其实实力不错,聚集了中科院语义理解方面的顶尖科学家。相比国外同行,rokid在算法能力上并不弱。作为一家中国公司,Rokid更了解中国的语言和文化习惯,在体验细节方面可以做得更好。此外,三家公司都具备软件核心技术+硬件设计制造能力。苹果的经验已经证明,硬件产品要做到极致,必须软硬件都控,软硬件结合才能做到极致体验。这也是为什么安卓手机在体验上永远比不上iphone的原因。
快捷
传统GUI下设置闹钟可能需要3分钟,而语音交互下只需要30秒。解放双手,不需要繁琐的操作app,可以一边忙着手头的事情,一边给机器下达语音任务。
可以看出,国内外科技巨头都在押宝语音交互产品,从集成在手机中的语音辅助工具,到独立的语音交互产品,这反映了语音交互的快速发展。
远场拾音的出现意义重大,是人机交互体验的突破。人们可以在家里的任何角落轻松地与
Echo交流。虽然苹果的siri,谷歌的google assistant,微软的cortana等语音助手很早就实现了对自然语义的理解,但都是近场的,使用起来有很多步骤。你需要拿出手机,启动助手,靠近他们说话。虽然比触控简单,但和远场拾音相比,体验上有本质差距。这种体验上的进化,只有经历过才能感受到。很多人可能没有用过这三款产品。然后参考之前的一个案例:在iphone出来之前,很多手机已经支持触控操作了,但是那时候触控是基于电阻屏的,需要手写笔。体验相比简单的键盘操作进化了不少,但还是不够自然。乔邦柱发明iphone一代的时候,一个重大创新就是电容屏的使用,可以直接支持手指触摸。这种交互方式更加自然,立刻成为主流。近场拾音音量像电阻屏,远场拾音更像电容屏,体验上有本质区别。对比亚马逊echo、google home、rokid pebble,它们在远场拾音方面的表现差不多,基本都能做到5米的正常拾音,而且各有特色。三校的远场识别都采用麦克风阵列+激活词。从技术上讲,麦克风越多,性能越好,成本越高。激活字越短,体验越好,技术难度越高。
3.语音交互消耗注意力,增加记忆负担。人与系统交互时,大多使用短时记忆,能记住的信息大概是15秒。语音交互不适合步骤多、信息量大的任务。每个人都有给银行服务打电话的经历。你必须集中精神,记住什么按1,什么按2,否则你得再听一遍。
语音交互属于人机交互的范畴,是人机交互最高级的交互方式:它是用人类的自然语言向机器发出指令以实现自己目标的过程。
语音交互和传统的文字交互并不是互斥的,非此即彼的关系。语音交互在某些场景会逐渐成为主流,而其他场景可以作为文字交互的补充。他们可以“共同生活,共同繁荣”。
1.语音交互不会成为主流交互方式,只会成为未来交互方式之一。
变化:从单屏交互到无处不在的交互。我们未来的界面不能再是大家认为的最传统的长方形,而可以是任何形状,就像自然界中的一个物体。