

2021年12月6日,CCF大数据与计算智能大赛(CCF Big Data & Computing Intelligence Contest,简称CCF BDCI)《机器翻译领域适应》算法竞赛结果出炉,科讯嘉联小嘉团队凭借优异的模型效果,荣获该赛第一名的好成绩。
机器翻译是利用计算机把一种自然源语言转变为另一种自然目标语言的过程,近年来,深度学习技术的飞速发展让机器翻译有了长足的进步,其生成的译文越来越接近自然句子,但机器翻译也同样面临着很多困境,一个典型的例子是口语化语料通常容易收集,具有富资源的特性,而纵深领域语料存在低资源问题,且还存在领域性词汇问题,这就导致当训练语料与实际领域不匹配的情况下错译率较高的问题,如何利用富资源领域的数据帮助低资源领域提升翻译质量也一直是翻译领域的研究重点。
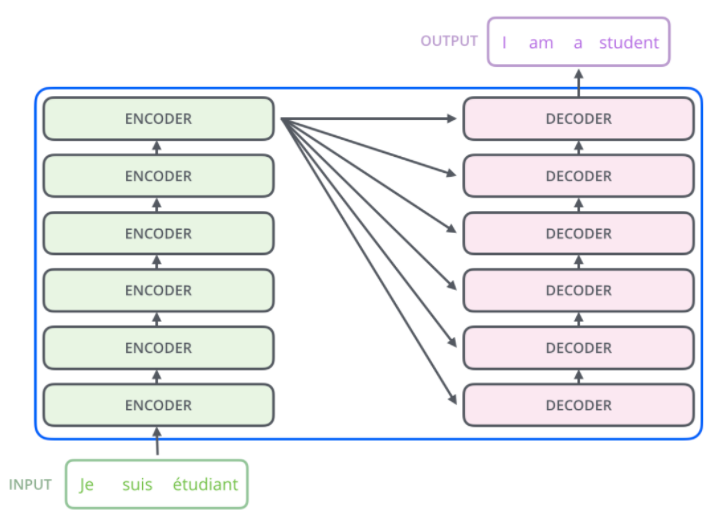
一般而言机器翻译中,采用6个transformer encoder blocks作为编码器,对源语言进行编码;采用6个transformer decoder blocks作为解码器进行解码,把源语言解码为目标语言。
为了解决低资源领域的数据不足问题,提高不同领域翻译效果,我们尝试了通用翻译预训练模型、本地模型回译式数据增强、对抗训练、自监督和后处理相结合的创新方法,选用MarianMTModel作为翻译任务的transformer架构模型(6层encoder和decoder模型),opus-mt-zh-en中文到英文的预训练模型,对口语领域的中英平行句对和专利领域的中英平行句进行中文到英文翻译的baseline模型训练,得到初版baseline。然后针对对专利领域的英文单语数据以及医药领域英文单语数据(共计30W)进行回译式数据增强,充分利用好单语数据,具体方法如下:
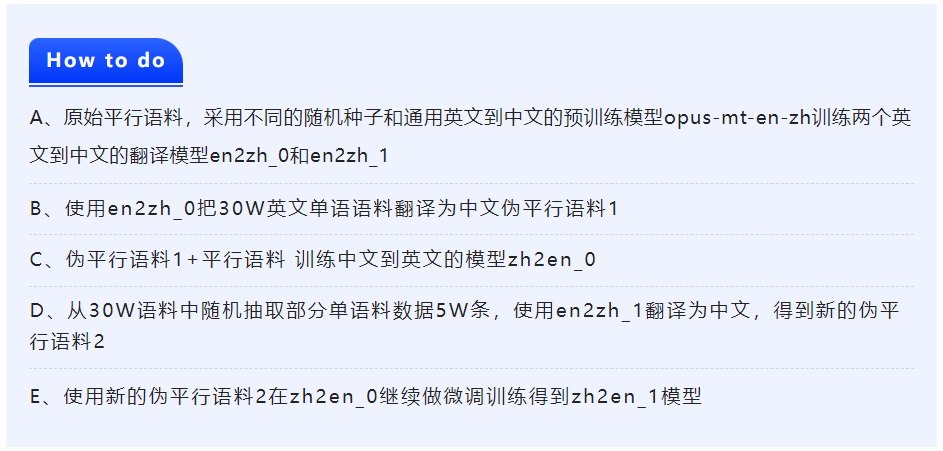
zh2en_1就是数据增强后的最佳模型,测试集中的专利和医药领域的句子翻译效果得到大幅度提升。再次,在以上训练的过程中引入对抗训练的思想,采用FGM对抗训练算法对embedding层参数进行对抗训练进一步提升模型的准确性和鲁棒性。最后,把zh2en_1模型对中文测试集翻译到英文的结果作为自监督的平行语料,和原始语料合并得到最新的中英文对平行语料,在opus-mt-zh-en做微调训练得到最终模型zh2en_final;使用zh2en_final模型对测试集进行翻译,结合后处理的方式——删除多余的标点符号、漏译的句子进行调整处理得到最终的提交结果。
经过多番的尝试与验证,融入了数据增强的理念,引入了对抗训练的思想,设计了后处理的环节,最终得到了在多个领域上具有不错翻译效果的模型,并最终在竞赛中取得了冠军。

随着中国经济的发展,具备多国语言客服的需求越来越多,本次获奖也意味着科讯嘉联始终践行,用AI客服,服务全球人民的理念。